카산드라(cassandra), 데이터를 읽고 쓰는 과정에서는 클라이언트에서 카산드라의 데이터를 읽는 절차를 가볍게 설명하였습니다. 이번 글에서는 데이터를 읽는 과정을 좀 더 자세히 설명하겠습니다.

가장 단순한 경로는 요청한 데이터를 디스크(SSTable)에서 읽는 것입니다. 그러나 해당 데이터를 디스크에서 바로 읽는 것은 매우 비용이 큽니다. 즉, 시간이 오래 걸립니다. 그래서 카산드라는 최대한 메모리에서 읽으려고 시도합니다.
위의 그림에서는 이름이 "홍길동"인 데이터를 찾는 과정을 도식화한 것입니다. 이해를 돕기 위해 데이터를 요청한 노드에 데이터가 존재한다고 가정합니다.
데이터 조회 요청 시
① "홍길동"의 번호 "1"을 조회 조건으로 입력하여 데이터를 요청합니다. 해당 요청을 받는 노드를 코디네이터 노드(coordinator node)라 합니다.
② 해당 데이터는 두 군데서 찾습니다. 하나는 Memtable이고 다른 하나는 SSTable입니다. 아직 SSTable에 저장되지 않은 데이터는 Memtable에서 가져오며 나머지는 SSTable에서 가져옵니다.
SSTable에서 데이터를 가져오는 절차
SSTable에서 데이터를 가져오는 절차는 조금 복잡하여 세분화하여 설명하겠습니다.
하나의 노드는 여러 개의 SSTable이 존재하므로 찾을 데이터가 어느 SSTable에 있는지 아는 것은 매우 중요합니다. 어느 SSTable인지 모른다면 모든 SSTable을 스캔해야하므로 매우 많은 시간이 소요될 것입니다. 블룸 필터(Bloom Filter)는 해당 데이터가 있는 SSTable의 위치를 찾는 데 도움을 줍니다.
③ 블룸 필터 (Bloom Filter)
해당 알고리즘을 개발한 Burton Bloom의 이름을 따서 명명한 Bloom Filter는 읽기 성능을 극대화하기 위한 장치입니다. Bloom Filter는 다음의 한 개의 단어로 표현할 수 있습니다.
- false-positive read
해당 표현을 간략히 설명하면 다음과 같습니다.
- false-positive read : bloom filter를 통과한 결과 데이터가 존재하는 SSTable의 위치를 알려주었지만 실제로는 해당 위치에 데이터가 없는 경우
한 마디로 bloom filter에서 알려준 데이터의 위치 정보에는 실제로는 데이터가 없을 수 있습니다. 그러나 반대로 데이터가 없다고 알려준 경우는 실제로 데이터가 없습니다. 이 알고리즘으로 데이터를 찾기 위해 SSTable을 탐침하는 경우 데이터를 누락할 염려는 없습니다. 이를 false-negative read라고 표현하기도 합니다. Bloom Filter 기능을 사용하려면 row-caching 옵션이 enabled 상태여야 합니다.

④ 파티션 키 캐시 (Partition Key Cache)
Bloom Filter를 통과하여 해당 SSTable의 위치를 알았다면 Partition Key Cache에 조회하려는 키(Key)에 해당하는 파티션 키(Partition Key)가 있는지 즉, 캐시된 상태인지 확인합니다. Partition Key가 Partition Key Cache에 존재한다면 SSTable을 모두 스캔할 필요 없이 해당 Partition Key가 있는 데이터만 부분적으로 읽을 수 있습니다.

⑤ 파티션 요약정보 (Partition Summary)
조회하려는 키(Key)에 해당하는 파티션 키(Partition Key)가 Partition Key Cache에 없는 경우 Partition Index(파티션 인덱스)를 통해 SSTable에 접근하기 위한 시도를 합니다. 이때 Partition Key로 Partition Index를 바로 접근하지 않고 Partition Index의 요약정보를 가진 Partition Summary를 통해 Partition Index의 위치 정보를 찾습니다.
⑥ 파티션 인덱스 (Partition Index)
파티션 인덱스(Partition Index)는 파티션 키(Partition Key)에 해당하는 SSTable 위치 정보를 가지고 있습니다. 조회하려는 Key로 해당 Partition Key에 해당하는 SSTable 위치 정보를 가져옵니다.
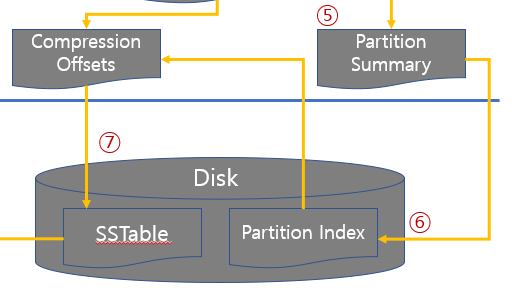
⑦ SSTable
파티션 인덱스(Partition Index)로 알게 된 위치 정보로 SSTable에서 해당 데이터를 읽습니다. 해당 데이터는 Memtable에서 읽은 데이터와 함께 조회한 클라이언트(Client)로 보내집니다.
'NoSQL > Cassandra DB' 카테고리의 다른 글
| 카산드라(cassandra), Commit Log, Memtable, SSTable (0) | 2021.08.11 |
|---|---|
| 카산드라(cassandra), 데이터를 저장하는 과정(심화) (0) | 2020.11.18 |
| 카산드라(cassandra), 데이터 저장 구조 - 클러스터링 키(Clustering Key) (0) | 2020.11.02 |
| 카산드라(cassandra), 데이터 저장 구조 - 키스페이스(Keyspace) (0) | 2020.10.23 |
| 카산드라(cassandra), Virtual Node(vnode) (0) | 2020.10.21 |